
Calibrating on Capability, Not Activity
AI-assisted engineering is now an expectation. It’s in performance reviews, hiring decisions, calibration conversations, and senior leadership’s productivity expectations. Which means there’s an awkward question hanging over a lot of teams right now: how do you actually measure whether someone is good at this? I lead platform engineering teams, so I’ve been working through this from a particular angle, but the underlying question is general.
The default answer in a lot of places seems to be: count things. AI-attributed pull requests. Tool adoption rates. Lines of AI-assisted code. Prompt counts. Self-reported “Stage X” claims pulled from one of the many maturity-model frameworks doing the rounds.
I want to make a case against that. Not against measurement, but against measuring activity and calling it capability.
The position, in one sentence
AI-assisted engineering is a capability worth investing in openly, measuring directly, and calibrating on what we can actually observe, not on what looks good in a slide.
I’ll caveat upfront: I’m figuring this out as I go, and the metrics list below is going to look different in six months. But I’m pretty sure the direction is right, even if the specifics aren’t.
What I think is worth measuring
Three layers, each with observable signals.
Team adoption
- Agent-readiness of the codebase. AGENTS.md (or equivalent) coverage, scriptable build and test commands, behavioural test density, error-message quality. The bar is “an agent can pick this up cold and get useful work done.”
- Agent-readiness for your consumers. If you build platforms or libraries that other teams rely on, are they easy for an agent to use? Skills, MCP servers, agent-friendly APIs, worked examples. “Easy for a human” is no longer the same as “easy for an agent,” and increasingly the second one matters more.
- Workflows that live in the team, not in one person’s terminal history. The engineer who has the slick workflow but never shares it is a productivity dead-end.
- Operational agents in regular use for glue work: meeting follow-ups, backlog hygiene, and on-call summarisation, with appropriate guardrails.
- Cross-team transfer. Patterns from one team picked up by another. This is often the strongest signal that a practice is real and not theatre.
Individual mastery
- Demonstrated progression in agentic delegation, evidenced by what an engineer has delegated and reviewed. Not by self-report.
- Quality of their own agent-assisted submissions, measured by review iteration required on substantive (i.e. non-trivial) work. Low-friction merges on real, complex pull requests are a strong signal that the AGENTS.md, the prompts, and the verification loop are doing real work. The engineer’s mature delegation design and self-review discipline are visible in the artefact.
- Quality of review on others’ agent-generated work. Catching the subtle errors that agents make with high confidence is a craft skill that compounds across the team.
- Ownership of context artefacts. AGENTS.md, runbooks, evaluation rubrics for components they own.
- Workflows, skills, or tools they’ve published that other engineers have adopted.
- Range of problems they’ll attempt agentically rather than hand-write, paired with judgement about when not to.
Two failure modes to watch out for: pull-request-size inflation that dilutes review density, and trivial-submission padding to game the iteration metric. The signal is comments-per-substantive-change on work that meets a complexity threshold, not raw cleanliness on safe submissions.
Craft signals
- Documented agent failure modes, evals, or guardrails contributed back to the team and the wider community of practice.
- Thoughtful scepticism translated into evaluation criteria, review checklists, or quality bars, rather than treated as a blocker.
The underlying skill all three layers point at is something Annie Vella has called the middle loop1: the supervisory work of directing AI, evaluating its output, and correcting where it falls short. It sits between the inner loop of craft activities (write, build, test, debug), already optimised by TDD and IDEs, and the outer loop (commit, review, CI, deploy), already optimised by DevOps. The middle loop is where the practice has shifted, and where conventions, tooling, and individual mastery are still being formed. Naming it helps; it gives engineers a concept to hang their development on, and gives reviewers something specific to look for.
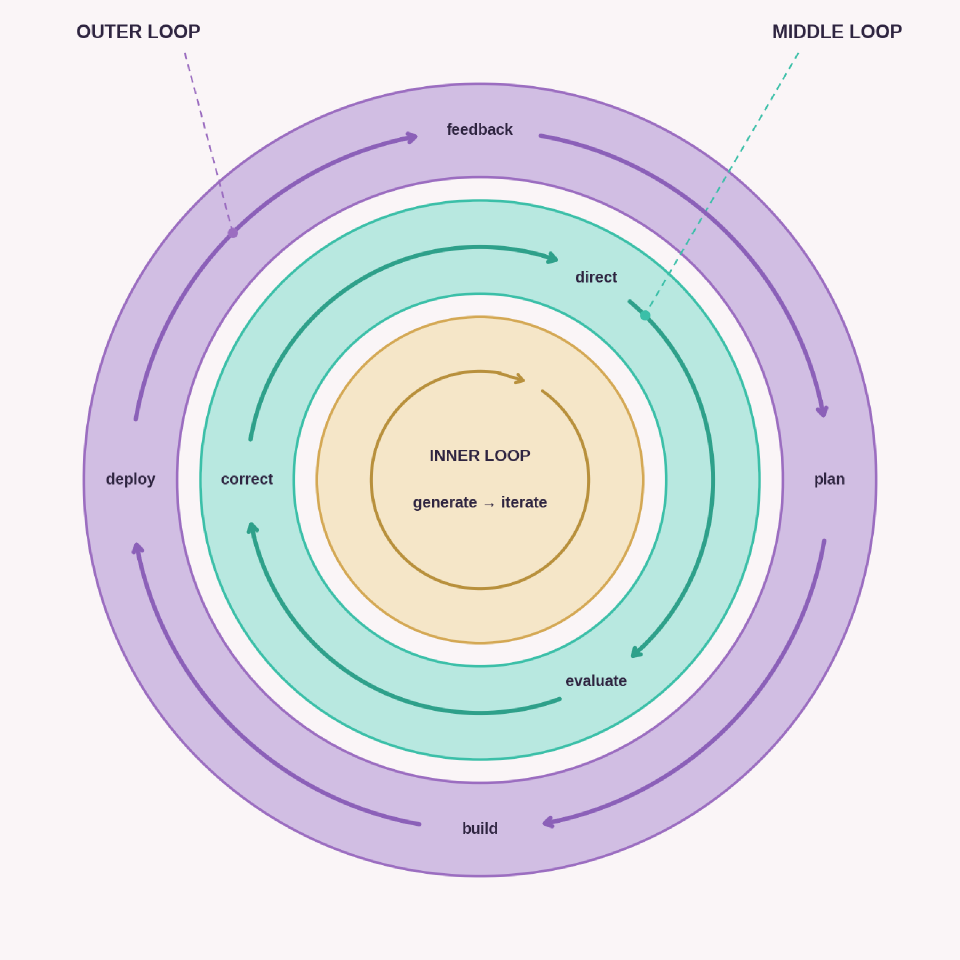
For example, a strong signal would be an engineer taking a messy, under-documented service and making it more agent-ready: adding the missing build and test instructions, tightening the error messages, capturing the agent failure modes they hit, and then showing the team how that changed the quality of the next few assisted changes. That is much more useful calibration evidence than knowing how many prompts they wrote.
What I’d refuse to measure
- Tool-usage telemetry, beyond a relatively binary “do you use AI”.
- Prompt counts, token counts, session counts.
- AI-attributed PR percentages or commit annotations.
- Lines of AI-assisted code shipped.
- Self-reported “Stage X” claims without behavioural evidence.
These metrics measure activity, not capability. They reward volume over judgement, theatre over substance, and they game easily. DORA’s 2025 State of AI Assisted Software Development2 is explicit on this: AI is best understood as an amplifier of underlying system quality, not an independent productivity input. Measure the system, not the tool usage.
The longer-running evidence agrees. The SPACE framework (Forsgren et al., 2021)3 predates the AI conversation and warns directly against single-metric activity counters; the same critique applies here, in a sharper form. GitClear’s multi-year analysis of around 211 million changed lines of code4 showed code churn rising and refactor rates falling as Copilot adoption increased. Volume metrics are getting less informative as AI adoption deepens, not more.
The throughput question
Throughput is the elephant in the room. I do believe AI-assisted engineering produces real second-order delivery gains. That belief is the motivation for investing in the capability in the first place. There’s no need to hide it.
But throughput isn’t the calibration frame. At the department/group level, lead time for change and change failure rate are reasonable lagging outcome signals. They let leadership ask whether the investment is paying off and get a credible answer. They shouldn’t be pushed down to individual or sprint-level calibration though. The signal is too noisy at that resolution. Similarly, the signal works at quarterly or half-yearly timescales, not sprint timescales. Platform work in particular has a long-tailed payoff structure that short-term metrics miss.
That, to me, is the discipline the position requires: invest because you believe in the second-order gain, calibrate on what you can actually observe.
A counter-argument worth taking seriously
I want to be honest about the strongest counter-evidence. Cui et al. (2024)5 ran a large field experiment across Microsoft, Accenture, and a Fortune 100 company with around 4,800 developers, and found a 26% increase in pull requests per week, with the largest gains for less-experienced developers. The effect can be significant, and I’m not disputing that.
I’d still refuse “pull requests per week” as a calibration metric, for three reasons:
- It incentivises volume over verified value, which is the failure mode I’m trying to avoid in the first place.
- The gains are heterogeneous across task types. Dell’Acqua et al. (2023)6 call this the “jagged frontier”: AI lifts performance on some tasks and degrades it on others, often in the same workflow, and the boundary isn’t always intuitive. Averaging across that boundary is misleading.
- The largest gains were seen in the engineers who most need critical-review skill development. Calibrating on PR volume would reward exactly the people who should be coached.
The METR study (July 2025)7 sharpens the picture further. Experienced developers in their own codebases were 19% slower with AI assistance, despite predicting a 24% speedup beforehand and reporting a 20% speedup afterwards. This is the part that hit home for me, leading platform teams. The working conditions of platform engineering (usually very senior teams, brownfield systems, complex domains, high reversibility cost) are much closer to the METR sample than to the greenfield Copilot benchmarks the louder productivity claims tend to come from. Self-report and adoption metrics diverge from actual productivity at exactly the scale where platform work actually happens. Treating them as calibration evidence would simply be wrong.
Vella’s longitudinal study of 158 professional engineers across 28 countries1 reinforces the point from a different angle: 84% reported productivity gains, while engineers reporting negative developer experience nearly doubled from 14% to 27% over six months. Self-reported productivity and lived experience moved in opposite directions, in the same population, in the same period.
What the trade-off costs
There’s no free lunch. If you ask not to be measured on activity, you owe more visibility on capability. For example:
- Public capability targets each planning cycle, framed in the language of the three layers above.
- Transparent show-and-tell of agentic work on real production code, not just personal productivity demos.
- Honest write-ups of what didn’t work, alongside what did.
- Active contribution back to the wider community of practice. AGENTS.md patterns, evals, workflows, and tooling that other groups can adopt.
Some of these signals are observable today (review iteration, AGENTS.md coverage, workflow adoption). Others need a baseline before they can be calibrated against (substantive PR thresholds, agent-readiness scoring, cross-team transfer signals). Building the instrumentation is part of the position, not a precondition for it.
This is not a finished scorecard, and I don’t think it should pretend to be one yet. The point is to move the calibration conversation toward observable capability: what changed in the codebase, what changed in the team’s workflows, what judgement improved, and what other people can now do because of it.
The human side of this
One last thing, and I’m flagging it more as a people-lead than as someone with a tidy answer. The stat I quoted earlier, where engineers reporting negative developer experience nearly doubled in six months while productivity self-reports stayed positive, is the bit that keeps nagging at me. It’s the kind of finding companies will likely ignore because DevX is hard to measure and doesn’t obviously impact the bottom line. But if you’re leading people, you can’t ignore it. The traditional sources of engineering satisfaction (writing the thing, debugging through your own logic, owning the solution end-to-end) are exactly the activities that can shrink when work shifts toward supervising agents. You can have a team that’s crushing it on every adoption metric and still be quietly disengaging. I don’t have a metric to suggest here. I just think it’s worth paying attention to in 1:1s, and being honest with your team about the trade-off rather than pretending this disruption and change in how we work comes without any downside.
The other thing worth saying, because it’s something I’ve actually been thinking about a lot, is that this is felt very unevenly across a team. Some engineers love it. They get their joy from the end result, the thing they built and shipped, and being able to crank out 10 widgets a week instead of 2 is bloody energising for them. Then there are the engineers who get their jollies from the journey: the careful crafting of 1 or 2 widgets a week, the satisfaction of solving the problem from first principles. For them, this shift can feel like being cheated out of the bit they actually enjoyed. Both are completely valid ways to derive meaning from the job. They just respond very differently to this transition.
The coaching response can’t be the same for both groups. For the journey-oriented folks especially, I think the work is helping them find reward in the new hard problems: designing complex agent harnesses, building feedback loops and evals, codifying what “good” actually looks like from a UI or UX perspective, the quality and success criteria that an agent can be measured against. There’s still craft in all of that, and arguably more of it than there used to be. It’s just a different shape of craft, and people need help finding their way into it rather than being told to “just embrace AI” and getting on with it.
TL;DR
The thing I keep coming back to is this: the work has changed shape. The creation-to-verification shift is happening (more quickly for some than others), and it’s recent enough that the metrics most organisations are reaching for were built for the “old shape”. Measuring how often someone presses the AI button, or what fraction of a PR is “AI-attributed,” is pointless in most cases.
The interesting question, the one I’d want an engineer to answer in a coaching or review conversation, isn’t how much they used AI. It’s what did they delegate, what did they catch in review that the agent got wrong with confidence (and what did they learn from this), what did they ship back to the team that made everyone else more capable, and where did they decide not to use it.
That’s a harder thing to measure, but I think today it’s the thing actually worth measuring.
Cheers, Dave
-
Vella, A. (2025). “The Middle Loop” https://annievella.com/posts/the-middle-loop/ ↩︎ ↩︎
-
Google Cloud / DORA. (2025). “2025 State of AI Assisted Software Development” https://cloud.google.com/resources/content/2025-dora-ai-assisted-software-development-report ↩︎
-
Forsgren, N. et al. (2021). “The SPACE of Developer Productivity.” https://queue.acm.org/detail.cfm?id=3454124 ↩︎
-
GitClear. (2024). “Coding on Copilot: Multi-Year Study of AI-Assisted Code Quality.” https://www.gitclear.com/coding_on_copilot_data_shows_ais_downward_pressure_on_code_quality ↩︎
-
Cui, Z. et al. (2024). “The Effects of Generative AI on Productivity, Quality, and Skill Development at a Large Software Company.” https://www.nber.org/papers/w32944 ↩︎
-
Dell’Acqua, F. et al. (2023). “Navigating the Jagged Technological Frontier.” https://www.hbs.edu/faculty/Pages/item.aspx?num=64700 ↩︎
-
METR. (2025). “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity.” https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/ ↩︎